SmileDetector — A New Approach to Live Smile Detection
A UTMIST Project by Noah Cristino, Bradley Mathi, Daniel Zhu, and Mishaal Kandapath.

Smile Detector detects smiles in images using a new multi-step approach, which consists of performing facial recognition and then running the detected facial vectors through our custom C-Support Vector Classification model. By reducing the model input size and approaching this problem in a new way, we were able to produce a model that can perform classifications with high accuracy in fractions of the time that traditional models take. This technology has many applications, including engagement analysis, marketing, and photography.
Motivation and Goal

The goal of this project was to utilize a machine learning model to be able to detect smiles in pictures and video footage. More specifically, we wanted to create a model that was more optimized and was able to run faster than previous models. Competing models use image input and attempt to find a smile in the full image, meaning that a lot more time is needed for computation. Our goal with this model was to use a hybrid approach that first uses the DLib library to turn the image into vector points. The ML model then directly analyzes those vector points, meaning there are far fewer data to process. We hoped this would lead to similarly accurate results and a much faster processing time.
Dataset

We used the GENKI-4000 Dataset compiled by the MPLab at UC San Diego to train our model. This dataset consists of 4,000 images that all contain faces that are either smiling or not smiling. This dataset is tagged with 1 = smiling, 0 = not smiling.
Data Processing

Our program takes the input image, resizes it, and converts it to grayscale. This image is then passed into the DLib model, and facial vectors are generated. We use the vector representing the bridge of the nose to rotate the facial vectors so that the nose bridge is perfectly vertical. The vectors are then localized to deal with the fact that the face can be a different size in each image. We then take these vectors and add the ones around the mouth to a list. This list is passed into our SVC model, which detects whether the image contains a smile or not.
Network Structure
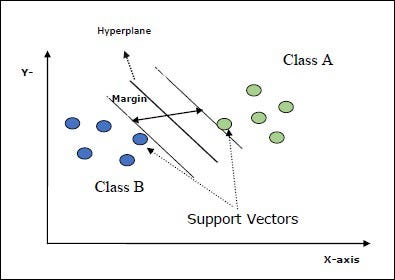
The DLib Facial Detect model uses a Histogram of Oriented Gradients (HOG) feature combined with a linear classifier, an image pyramid, and a sliding window detection scheme described in this paper. This model is pretrained and provided in the DLib python library. Our SVC model was trained using lists of vectors as input data, which mapped to a list of booleans that indicate smiling or not smiling.
Additional Features

In addition to creating the basic smile detector, We were able to use the same model to create a video parsing feature. Using this feature, one would be able to upload a video, and then receive an edited version of that video containing only the sections where someone is smiling. This worked by analyzing keyframes in the video to see if they were smiling or not, as opposed to processing the entire video, which made for faster processing times. Using this technique, we were able to process large video files in a relatively short amount of time and increase the usefulness of the model we created.
Future Applications

Live video smile detection has many potential uses in products or features to increase the quality of life of a consumer. For example, this technology could be used to create a feature for a camera app that would take pictures whenever the subject was smiling. This could be especially useful for taking pictures of children or babies, as it is often difficult to keep them smiling for long periods. Another use for this technology would be as a passive application that someone could enable while watching videos or streaming content. This would allow someone to see how much they smiled while watching the content and could be used to gauge how much someone enjoyed the video/stream they were watching.
Conclusion
Our project resulted in a much faster model than competing smile detection models while maintaining high accuracy. The speed allowed us to perform a live video analysis up to 720 FPS, allowing us to analyze webcam footage in real-time. This makes it possible to use our model for applications previously not possible with other competing models. Furthermore, we can analyze higher resolution cameras in real-time and run our model alongside others due to its small size. This allows us to generate additional data that can be used alongside the user’s emotion for analyzing engagement. Shrinking the number of required resources to create a faster model has allowed us to use this technology in new ways and outperform existing models.